Abstract
Although singing voice synthesis (SVS) has made significant progress recently, with its unique styles and various genres, Chinese opera synthesis requires greater attention but is rarely studied for lack of training data and high expressiveness. In this work, we build a high-quality Gezi Opera (a type of Chinese opera popular in Fujian and Taiwan) audio-text alignment dataset and formulate specific data annotation methods applicable to Chinese operas. We propose FT-GAN, an acoustic model for fine-grained tune modeling in Chinese opera synthesis based on the empirical analysis of the differences between Chinese operas and pop songs. To further improve the quality of the synthesized opera, we propose a speech pre-training strategy for additional knowledge injection. The experimental results show that FT-GAN outperforms the strong baselines in SVS on the Gezi Opera synthesis task. Extensive experiments further verify that FT-GAN performs well on synthesis tasks of other operas such as Peking Opera.
Dataset
Code
Contents
Audio Samples 1.1 Audio Quality Extensional Studies 2.1 Speech pretraining 2.2 Peking opera synthesis Dataset Info
Audio Samples
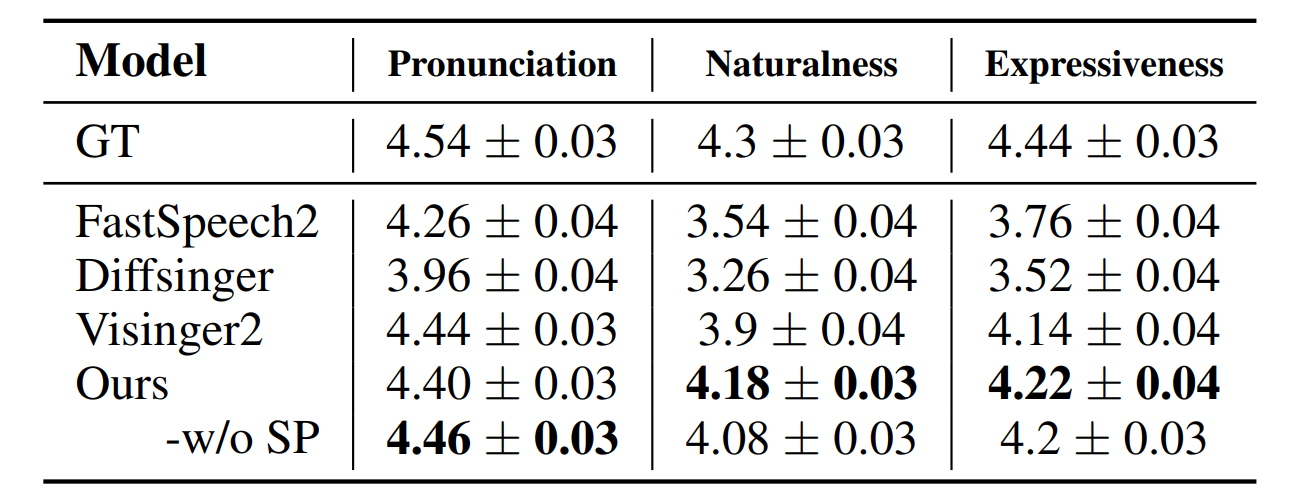
Audio Quality
我怎忍心割舍啊ua tsai lim sim kuah sia ah
Recording
Diffsinger
Fastspeech2
Visinger2
Ours
Your browser does not support the audio element. Your browser does not support the audio element. Your browser does not support the audio element. Your browser does not support the audio element. Your browser does not support the audio element.
看来此冤今生难得报khuann lai tshu uan kim sing lan tit poo
Recording
Diffsinger
Fastspeech2
Visinger2
Ours
Your browser does not support the audio element. Your browser does not support the audio element. Your browser does not support the audio element. Your browser does not support the audio element. Your browser does not support the audio element.
好比万箭穿呃我心呐hok pi ban tsinn tshuan leh gua sim na
Recording
Diffsinger
Fastspeech2
Visinger2
Ours
Your browser does not support the audio element. Your browser does not support the audio element. Your browser does not support the audio element. Your browser does not support the audio element. Your browser does not support the audio element.
笙歌同调琴瑟同音sing ko tong tiau khim sik tong im
Recording
Diffsinger
Fastspeech2
Visinger2
Ours
Your browser does not support the audio element. Your browser does not support the audio element. Your browser does not support the audio element. Your browser does not support the audio element. Your browser does not support the audio element.
你本是大宋栋梁臣li pun si tai song tong liong sin
Recording
Diffsinger
Fastspeech2
Visinger2
Ours
Your browser does not support the audio element. Your browser does not support the audio element. Your browser does not support the audio element. Your browser does not support the audio element. Your browser does not support the audio element.
Extensional Studies
Speech pretraining
二次战鼓已催过li tshu tsian koo i tshui ke
w/ speech pretraining
w/o speech pretraining
Your browser does not support the audio element. Your browser does not support the audio element.
看来此冤今生难得报khuann lai tshu uan kim sing lan tit poo
w/ speech pretraining
w/o speech pretraining
Your browser does not support the audio element. Your browser does not support the audio element.
你本是杨家传宗将li pun si iunn ka thuan tsong tsiong
w/ speech pretraining
w/o speech pretraining
Your browser does not support the audio element. Your browser does not support the audio element.
Peking opera synthesis
我本是一穷儒啊
Recoding
Diffsinger
Fastspeech2
DurIAN
ours
Your browser does not support the audio element. Your browser does not support the audio element. Your browser does not support the audio element. Your browser does not support the audio element. Your browser does not support the audio element.
冒犯了老太师府门庭
Recoding
Diffsinger
Fastspeech2
DurIAN
ours
Your browser does not support the audio element. Your browser does not support the audio element. Your browser does not support the audio element. Your browser does not support the audio element. Your browser does not support the audio element.
念卑人结发糟糠
Recoding
Diffsinger
Fastspeech2
DurIAN
ours
Your browser does not support the audio element. Your browser does not support the audio element. Your browser does not support the audio element. Your browser does not support the audio element. Your browser does not support the audio element.
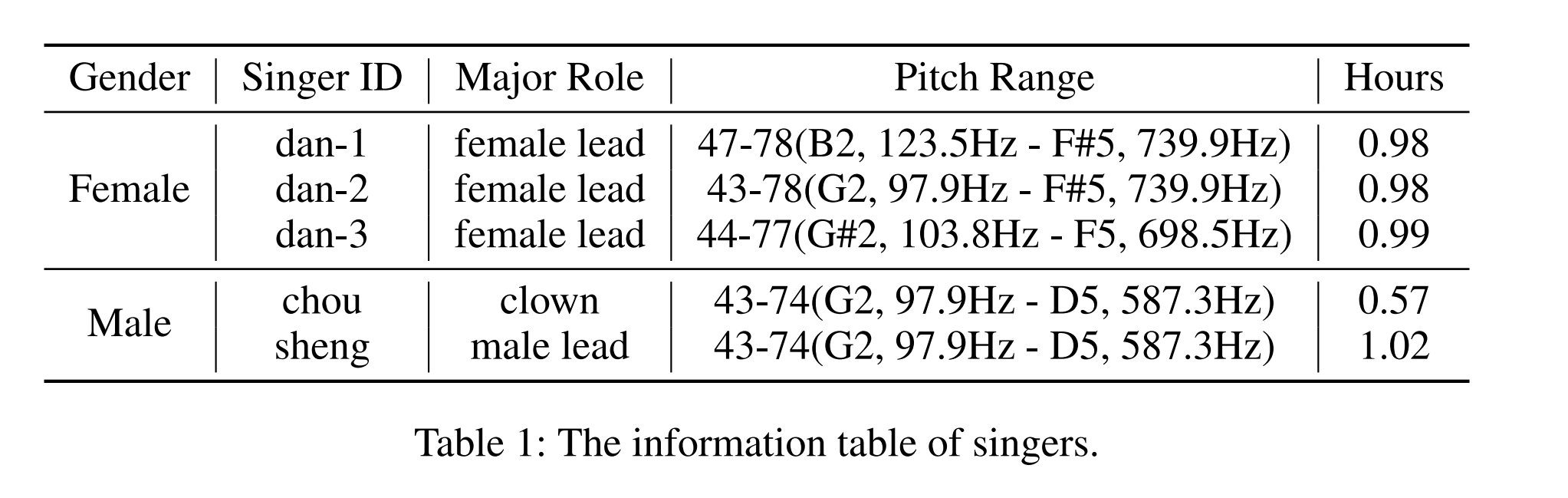
Dataset Info
FastSpeech 2: Fast and High-Quality End-to-End Text to Speech DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism VISinger 2: High-Fidelity End-to-End Singing Voice Synthesis Enhanced by Digital Signal Processing Synthesizer Peking Opera Synthesis via Duration Informed Attention Network